GPG signature verification failed for ‘/usr/local/rvm/archives/rvm-1.29.3.tgz‘ - ‘https://github.com/rvm/rvm/releases/download/1.29.3/1.29.3.tar.gz.asc‘! Try to install GPG v2 and then fetch the public key:
go get -u -d github.com/CodisLabs/codis cd $GOPATH/src/github.com/CodisLabs/codis make make gotest mkdir -p /usr/local/codis/{logs,conf,scripts} cp –rf bin /usr/local/codis/ cp config.ini /usr/local/codis/conf/
Codis-HA 编译 Codis-HA。这是一个通过 Codis 开放的 api 实现自动切换主从的工具。该工具会在检测 到 master 挂掉的时候将其下线并选择其中一个 slave 提升为 master 继续提供服务。 go get github.com/ngaut/codis-ha cd codis-ha go build codis-ha –codis-config=localhost:18087 –productName=test
20 admin_addr = “10.173.225.60:11080” 21 22 # Set bind address for proxy, proto_type can be “tcp”, “tcp4”, “tcp6”, “unix” or “unixpacket”. 23 proto_type = “tcp4” 24 proxy_addr = “10.173.225.60:19000” 26 # Set jodis address & session timeout 27 # 1. jodis_name is short for jodis_coordinator_name, only accept “zookeeper” & “etcd”. 28 # 2. jodis_addr is short for jodis_coordinator_addr 29 # 3. jodis_auth is short for jodis_coordinator_auth, for zookeeper/etcd, “user:password” is accepted. 30 # 4. proxy will be registered as node: 31 # if jodiscompatible = true (not suggested):32 # /zk/codis/db{PRODUCT_NAME}/proxy-{HASHID} (compatible with Codis2.0) 33 # or else 34 # /jodis/{PRODUCT_NAME}/proxy-{HASHID} 35 jodis_name = “” 3 # jodis_addr不能写地址,不然启动报错,不知道为啥,可能没有安装jodis, 36 jodis_addr = “” 37 jodis_auth = “” 38 jodis_timeout = “20s”
48 # bind 127.0.0.1 ::1 49 # 50 # WARNING If the computer running Redis is directly exposed to the 51 # internet, binding to all the interfaces is dangerous and will expose the 52 # instance to everybody on the internet. So by default we uncomment the 53 # following bind directive, that will force Redis to listen only into 54 # the IPv4 lookback interface address (this means Redis will be able to 55 # accept connections only from clients running into the same computer it 56 # is running). 57 # 58 # IF YOU ARE SURE YOU WANT YOUR INSTANCE TO LISTEN TO ALL THE INTERFACES 59 # JUST COMMENT THE FOLLOWING LINE. 60 # ~~ 61 bind 0.0.0.0 ……. ……. 82 # Accept connections on the specified port, default is 6379 (IANA #815344). 83 # If port 0 is specified Redis will not listen on a TCP socket. 84 port 6379
sentinel.conf
48 # bind 127.0.0.1 ::1 49 # 50 # WARNING If the computer running Redis is directly exposed to the 51 # internet, binding to all the interfaces is dangerous and will expose the 52 # instance to everybody on the internet. So by default we uncomment the 53 # following bind directive, that will force Redis to listen only into 54 # the IPv4 lookback interface address (this means Redis will be able to 55 # accept connections only from clients running into the same computer it 56 # is running). 57 # 58 # IF YOU ARE SURE YOU WANT YOUR INSTANCE TO LISTEN TO ALL THE INTERFACES 59 # JUST COMMENT THE FOLLOWING LINE. 60 #~~ 61 bind 0.0.0.0 ……. ……. 82 # Accept connections on the specified port, default is 6379 (IANA #815344). 83 # If port 0 is specified Redis will not listen on a TCP socket. 84 port 26379
通过web浏览器访问集群管理页面(fe地址:127.0.0.1:8080) 选择我们刚搭建的集群 codis-demo,在 Proxy 栏可看到我们已经启动的 Proxy, 但是 Group 栏为空,因为我们启动的 codis-server 并未加入到集群 添加 NEW GROUP,NEW GROUP 行输入 1,再点击 NEW GROUP 即可 添加 Codis Server,Add Server 行输入我们刚刚启动的 codis-server 地址,添加到我们刚新建的 Group,然后再点击 Add Server 按钮即可,如下图所示
通过fe初始化slot
新增的集群 slot 状态是 offline,因此我们需要对它进行初始化(将 1024 个 slot 分配到各个 group),而初始化最快的方法可通过 fe 提供的 rebalance all slots 按钮来做,如下图所示,点击此按钮,我们即快速完成了一个集群的搭建。 每次增加组之后就需要重新执行Rebalance All Slots
// serverHandler delegates to either the server's Handler or // DefaultServeMux and also handles "OPTIONS *" requests. type serverHandler struct { srv *Server }
//Handle registers the handler for the given pattern. // If a handler already exists for pattern, Handle panics. func(mux *ServeMux)Handle(pattern string, handler Handler) { mux.mu.Lock() defer mux.mu.Unlock()
if pattern == "" { panic("http: invalid pattern " + pattern) } if handler == nil { panic("http: nil handler") } if mux.m[pattern].explicit { panic("http: multiple registrations for " + pattern) }
开发程序其中很重要的一点是测试,我们如何保证代码的质量,如何保证每个函数是可运行,运行结果是正确的,又如何保证写出来的代码性能是好的,我们知道单元测试的重点在于发现程序设计或实现的逻辑错误,使问题及早暴露,便于问题的定位解决。对一个包做(单元)测试,需要写一些可以频繁(每次更新后)执行的小块测试单元来检查代码的正确性。于是我们必须写一些 Go 源文件来测试代码。测试程序必须属于被测试的包,并且文件名满足这种形式 *_test.go,所以测试代码和包中的业务代码是分开的。
package even import"testing" funcTestEven(t *testing.T) { if !Even(10) { //!Even(10)==false,不会向下执行 t.Log("10 must be even") t.Fail() } if Even(7) { t.Log("7 is not even") t.Fatal() } if Even(10) { //Even(10)==true,但是为了测试,让它执行t.Log()和 t.Fail() t.Log("Everything OK: 10 is even, just a test to see failed output!") t.Fail() } } funcTestOdd(t *testing.T) { if !Odd(11) { t.Log(" 11 must be odd!") t.Fail() } if Odd(10) { t.Log(" 10 is not odd!") t.Fail() } }
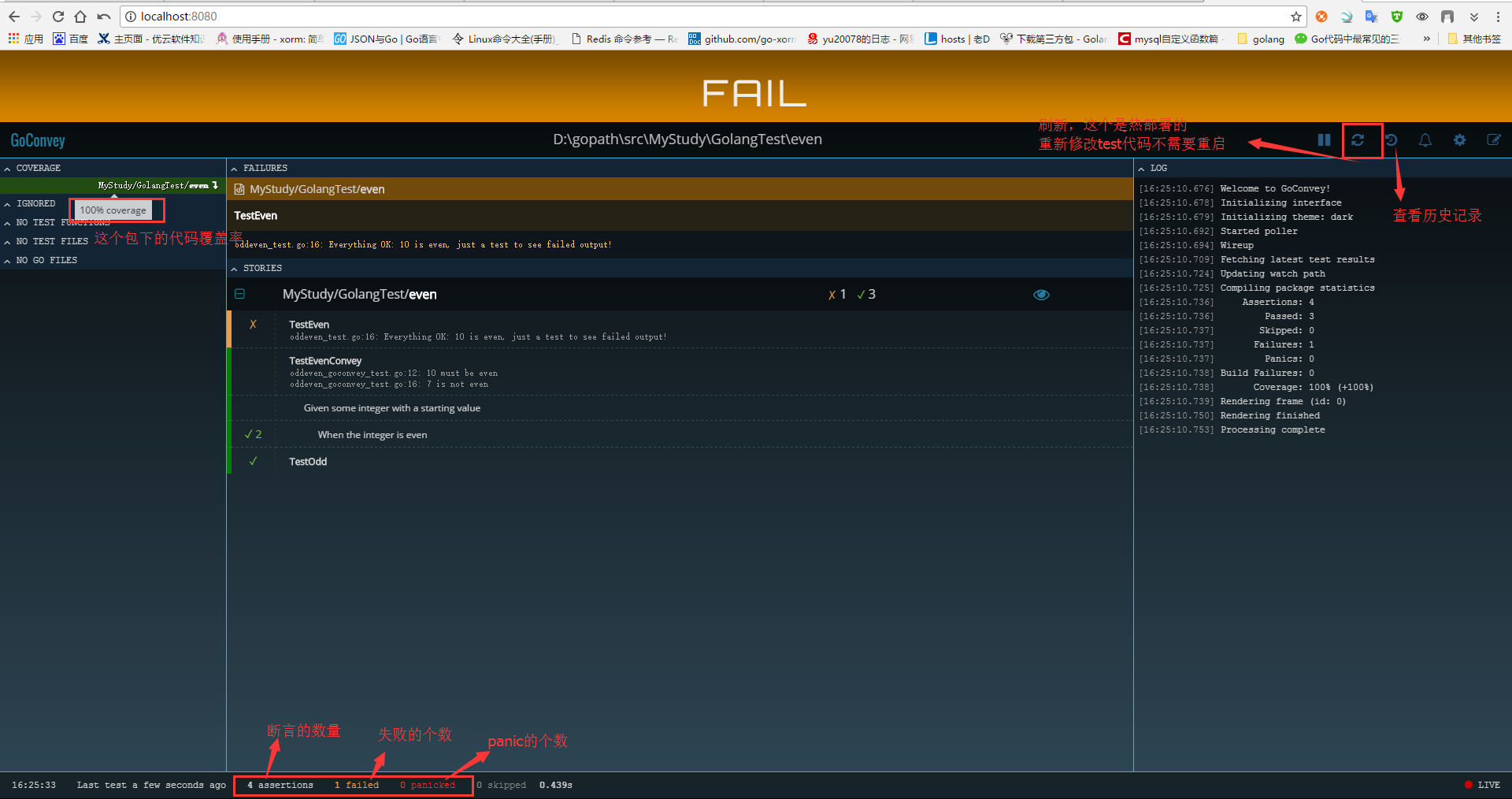
使用go test 运行oddeven_test.go,只会出现错误信息
— FAIL: TestEven (0.00s)
1 2
> oddeven_test.go:16: Everything OK: 10 is even, just a test to see failed output! >
FAIL exit status 1 FAIL MyStudy/GolangTest/even 0.364s
使用go test -v,会将详细的信息都打印出来,通过的会有pass标识
=== RUN TestEven — FAIL: TestEven (0.00s)
1 2
> oddeven_test.go:16: Everything OK: 10 is even, just a test to see failed output! >
=== RUN TestOdd — PASS: TestOdd (0.00s) FAIL exit status 1 FAIL MyStudy/GolangTest/even 0.397s
1.2单元测试的一些通知失败的方法
1)func (t *T) Fail()
1
标记测试函数为失败,然后继续执行(剩下的测试)。
2)func (t *T) FailNow()
1
标记测试函数为失败并中止执行;文件中别的测试也被略过,继续执行下一个文件。
3)func (t *T) Log(args ...interface{})
1
args 被用默认的格式格式化并打印到错误日志中。
4)func (t *T) Fatal(args ...interface{})
1
结合 先执行 3),然后执行 2)的效果。
GoGonvey框架写单元测试
1、GoGonvey框架介绍
Go 语言虽然自带单元测试功能,在 GoConvey 诞生之前也出现了许多第三方辅助库。但没有一个辅助库能够像 GoConvey 这样优雅地书写代码的单元测试,简洁的语法和舒适的界面能够让一个不爱书写单元测试的开发人员从此爱上单元测试。
funcTestEvenConvey(t *testing.T) { Convey("Given some integer with a starting value", t, func() { Convey("When the integer is even", func() { //第一个Convey需要t参数,以后的不需要了 Convey("10 must be even", func() { b := Even(10) So(b, ShouldBeTrue) })
Convey("7 is not even", func() { b := Even(7) So(b, ShouldBeFalse) })
Convey("Everything OK: 10 is even, just a test to see failed output!", func() { b := Even(10) So(b, ShouldBeFalse) })
现在,可以打开命令行,然后输入go test -v来进行测试。由于 GoConvey 兼容 Go 原生的单元测试,因此我们可以直接使用 Go 的命令来执行测试。
=== RUN TestEvenConvey
Given some integer with a starting value When the integer is even 10 must be even . 7 is not even . Everything OK: 10 is even, just a test to see failed output! x
funcconnectToDB() { fmt.Println("ok, connected to db") }
funcdisconnectFromDB() { fmt.Println("ok, disconnected from db") }
funcdoDBOperations() { connectToDB() fmt.Println("Defering the database disconnect.") defer disconnectFromDB() //function called here with defer fmt.Println("Doing some DB operations ...") fmt.Println("Oops! some crash or network error ...") fmt.Println("Returning from function here!") return//terminate the program // deferred function executed here just before actually returning, even if // there is a return or abnormal termination before }
输出:
1 2 3 4 5 6
ok, connected to db Defering the database disconnect. Doing some DB operations ... Oops! some crash or network error ... Returning from function here! ok, disconnected from db
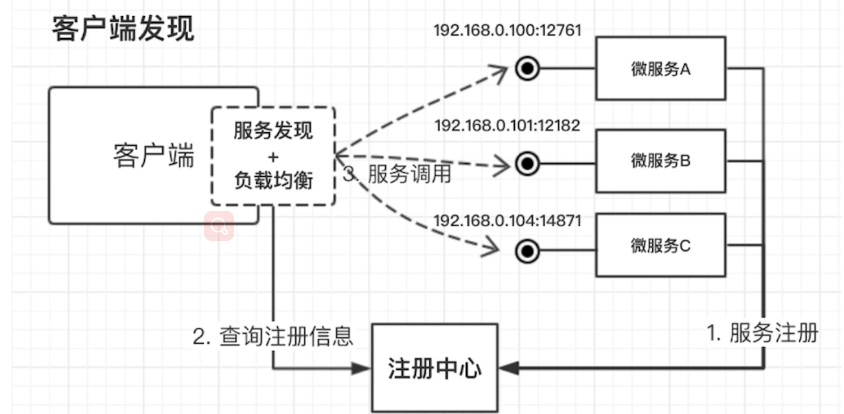
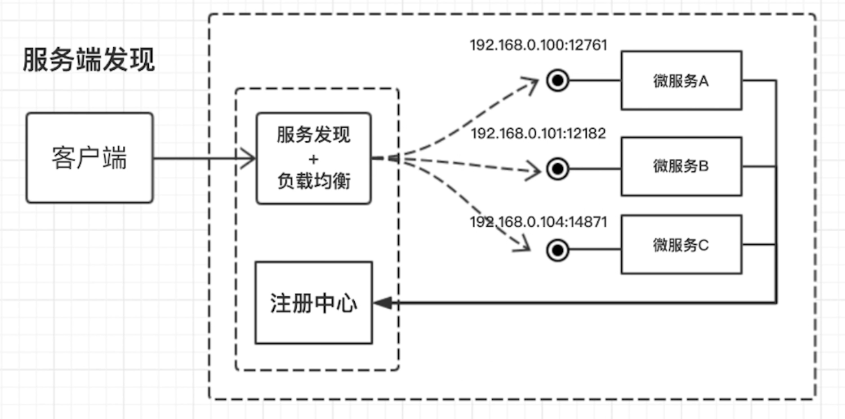
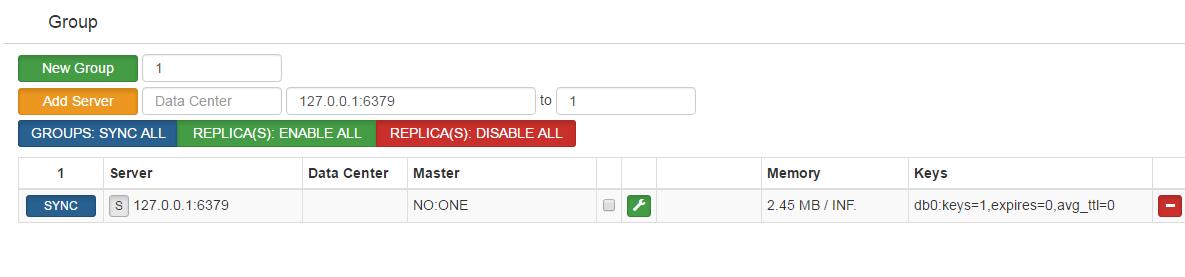
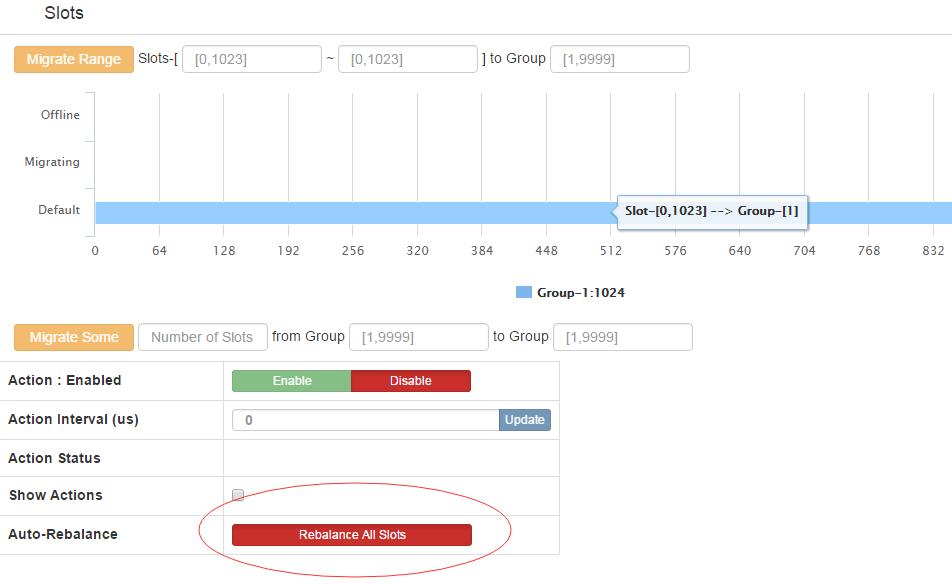

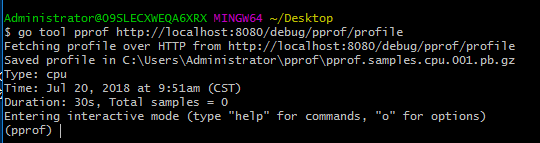
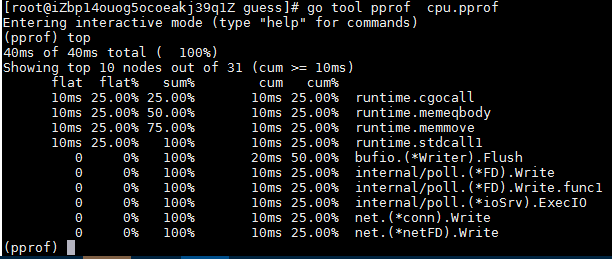
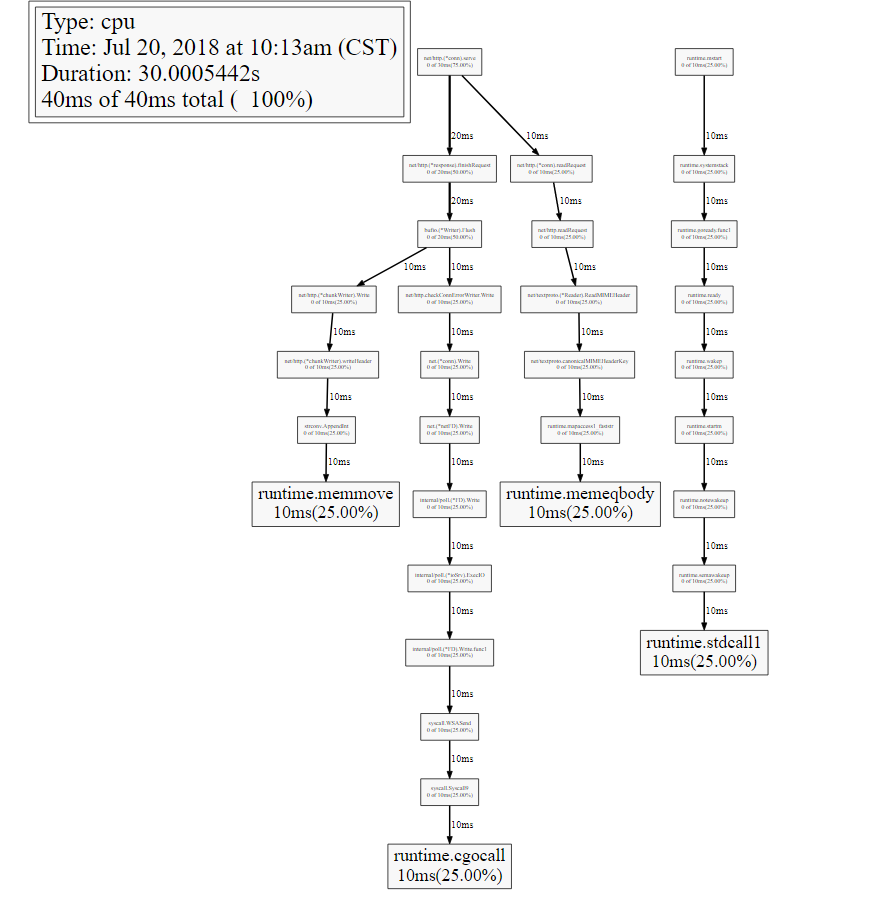
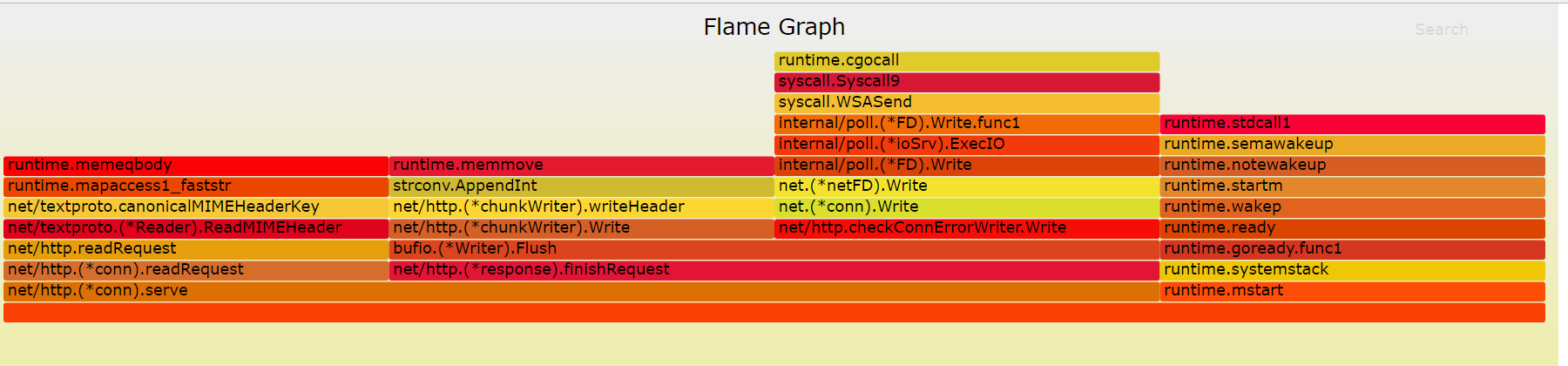
 。您的浏览器页面将自动更新。
。您的浏览器页面将自动更新。