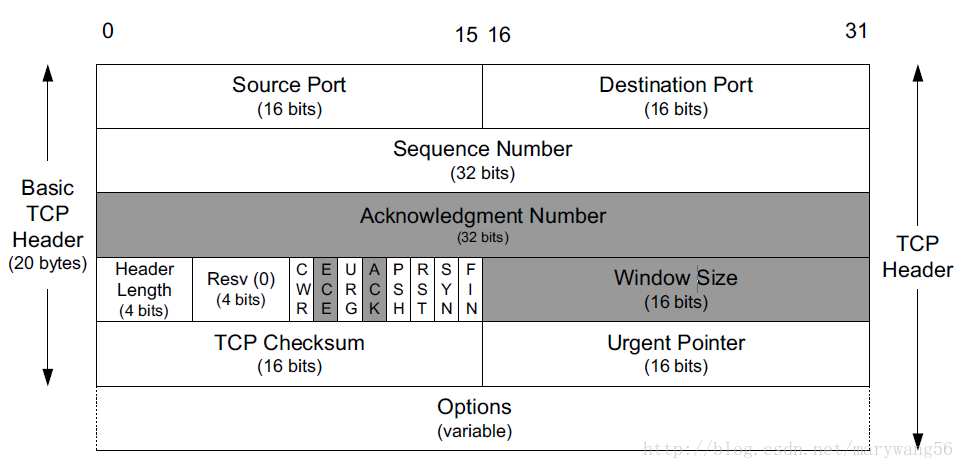
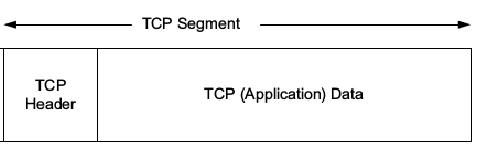
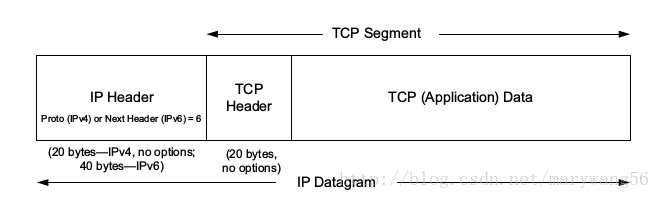
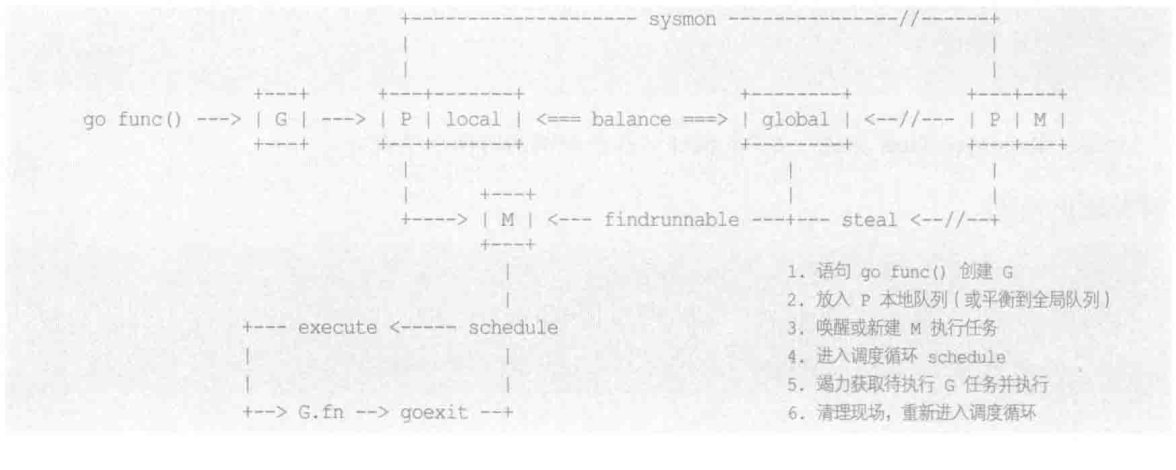
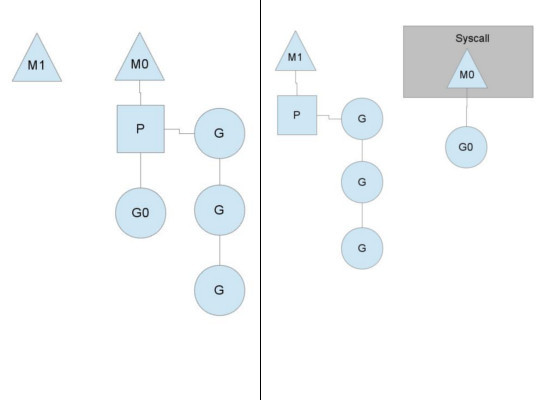
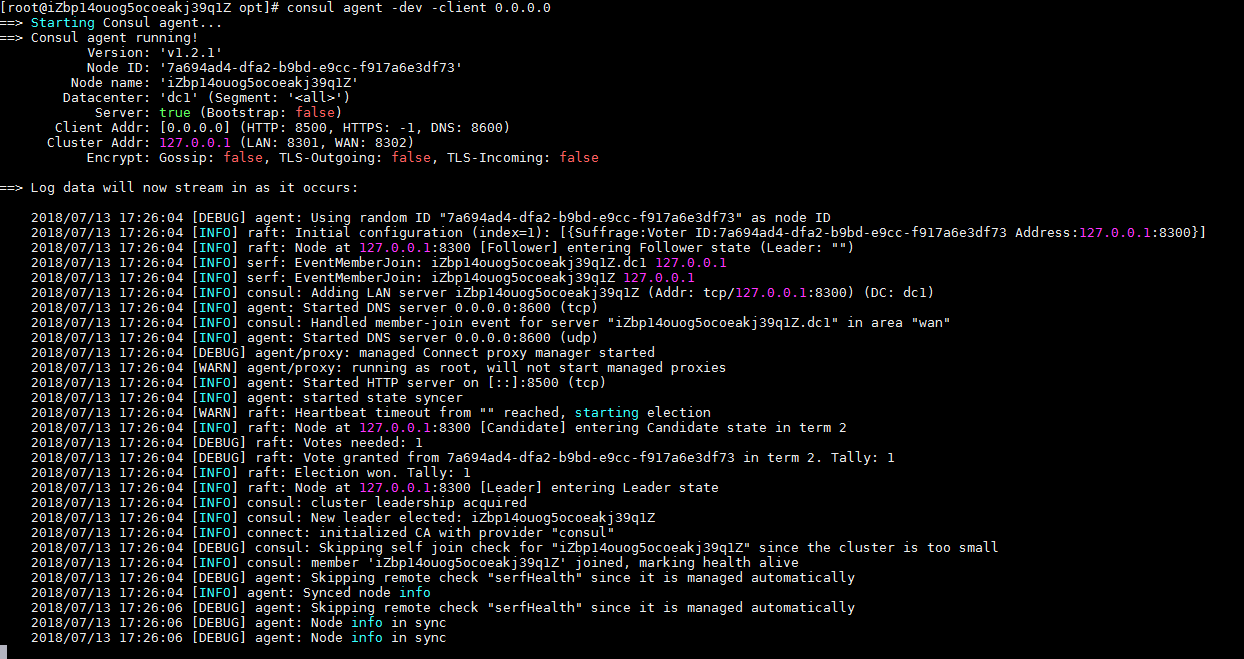
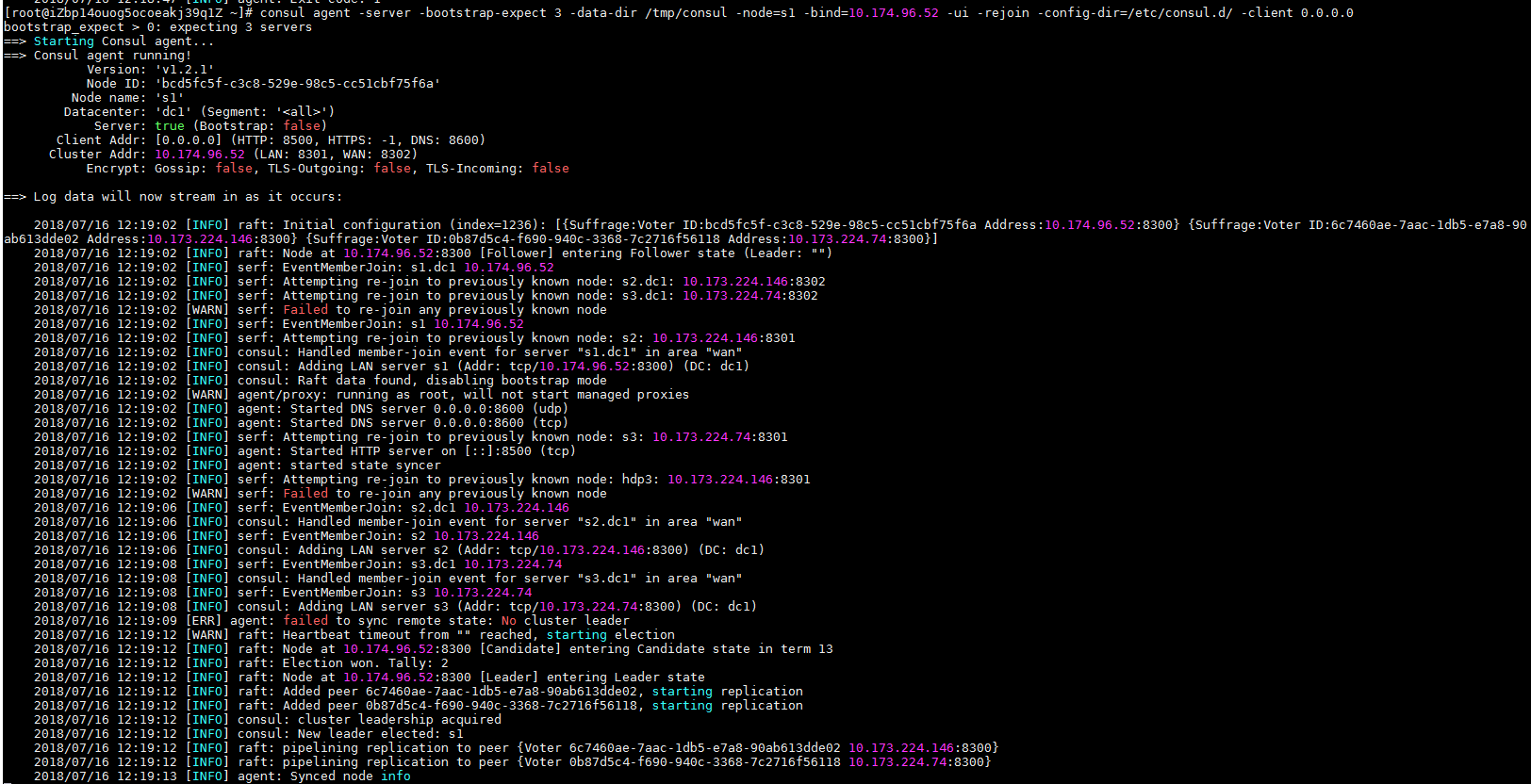
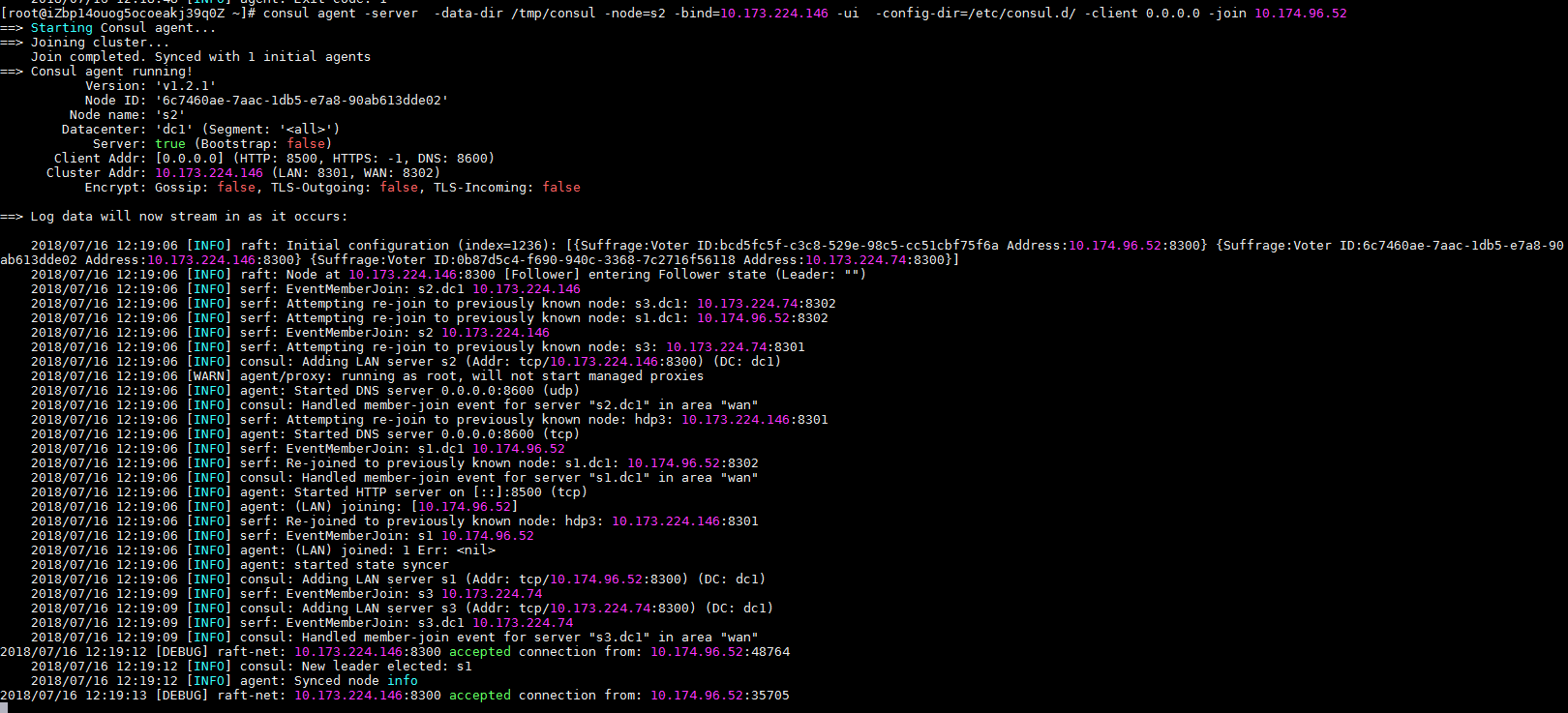
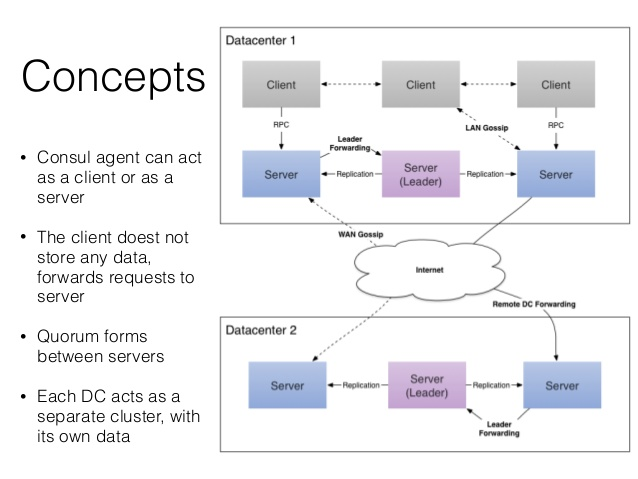
docker组成
docker 分为镜像,容器,仓库三部分。
- 仓库:可以说是类似是github一样的东西,github是存放代码的地方,dockerhub是存放docker镜像的地方
- 镜像:可以认为是我们的源代码,可以根据源代码编译成执行文件(容器)
- 容器:可以类比是各类软件(软件由代码编译,容器由镜像编译成),由docker镜像生成。
docker安装
docker现在分为ce和ee版本
ce(community-edition)版本是社区办,ee(enterprise-edition)是企业版
| 社区版 | 企业版基本 | 企业版标准 | 企业版高级 | |
|---|---|---|---|---|
| 容器引擎,built in orchestration, 网络, 安全 | yes |
yes |
yes |
yes |
| Docker认证的基础架构,插件和ISV容器 | yes |
yes |
yes |
|
| image管理(私有docker registry, caching) | Cloud hosted repos | yes |
yes |
|
| Docker数据中心(集成容器应用程序管理) | yes |
yes |
||
| Docker数据中心(RBAC, LDAP/AD support) | yes |
yes |
||
| 集成加密管理,镜像签名策略(Integrated secrets mgmt, image signing policy) | yes |
yes |
||
| 镜像安全扫描(Image security scanning) | Preview | yes |
||
| Support | Community Support | Business Day or Business Critical | Business Day or Business Critical | Business Day or Business Critical |
| 免费 | 750$/年 | 1500$/年 | 2000$/年 |
Ubuntu 安装 Docker CE
1 | $ sudo apt-get install docker |
启动 Docker CE
1 | sudo systemctl enable docker |
建立 docker 用户组
默认情况下,docker 命令会使用 Unix socket 与 Docker 引擎通讯。而只有 root 用户和 docker 组的用户才可以访问 Docker 引擎的 Unix socket。出于安全考虑,一般 Linux 系统上不会直接使用 root 用户。因此,更好地做法是将需要使用 docker 的用户加入 docker 用户组。
建立 docker 组:
1 | $ sudo groupadd docker |
将当前用户加入 docker 组:
1 | $ sudo usermod -aG docker $USER |
镜像加速
鉴于国内网络问题,后续拉取 Docker 镜像十分缓慢,强烈建议安装 Docker 之后配置 国内镜像加速。
镜像
获取镜像
从 Docker 镜像仓库获取镜像的命令是 docker pull。其命令格式为:
1 | docker pull [选项] [Docker Registry 地址[:端口号]/]仓库名[:标签] |
具体的选项可以通过 docker pull --help 命令看到。
- Docker 镜像仓库地址:地址的格式一般是
<域名/IP>[:端口号]。默认地址是 Docker Hub。 - 仓库名:如之前所说,这里的仓库名是两段式名称,即
<用户名>/<软件名>。对于 Docker Hub,如果不给出用户名,则默认为library,也就是官方镜像。
1 | sudo docker pull redis |
如果docker pull没有给出镜像地址,就会默认从docker hub下下载镜像
列出镜像
可以通过docker image来查看本地有哪些镜像
~$ sudo docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
wordpress latest 3745a1731caf 40 hours ago 408MB
mysql latest 29e0ae3b69b9 2 weeks ago 484MB
redis latest 4e8db158f18d 3 weeks ago 83.4MB
列表包含了仓库名、标签、镜像 ID、创建时间以及所占用的空间。
虚悬镜像
有时候有些镜像显示的是<none>。:
1 | <none> <none> 00285df0df87 5 days ago 342 MB |
这个镜像原本是有镜像名和标签的,原来为 mongo:3.2,随着官方镜像维护,发布了新版本后,重新 docker pull mongo:3.2 时,mongo:3.2 这个镜像名被转移到了新下载的镜像身上,而旧的镜像上的这个名称则被取消,从而成为了 <none>。除了 docker pull 可能导致这种情况,docker build 也同样可以导致这种现象。由于新旧镜像同名,旧镜像名称被取消,从而出现仓库名、标签均为 <none> 的镜像。这类无标签镜像也被称为 虚悬镜像(dangling image) ,可以用下面的命令专门显示这类镜像:
1 | $ docker images -f dangling=true |
一般来说,虚悬镜像已经失去了存在的价值,是可以随意删除的,可以用下面的命令删除。
1 | $ docker image prune |
中间层镜像
为了加速镜像构建、重复利用资源,Docker 会利用 中间层镜像。所以在使用一段时间后,可能会看到一些依赖的中间层镜像。默认的 docker image ls 列表中只会显示顶层镜像,如果希望显示包括中间层镜像在内的所有镜像的话,需要加 -a 参数。
1 | $ docker image ls -a |
这样会看到很多无标签的镜像,与之前的虚悬镜像不同,这些无标签的镜像很多都是中间层镜像,是其它镜像所依赖的镜像。这些无标签镜像不应该删除,否则会导致上层镜像因为依赖丢失而出错。实际上,这些镜像也没必要删除,因为之前说过,相同的层只会存一遍,而这些镜像是别的镜像的依赖,因此并不会因为它们被列出来而多存了一份,无论如何你也会需要它们。只要删除那些依赖它们的镜像后,这些依赖的中间层镜像也会被连带删除。
删除本地镜像
如果要删除本地的镜像,可以使用 docker image rm 命令或者docker rmi,其格式为:
1 | $ docker image rm [选项] <镜像1> [<镜像2> ...] |
1 | $ docker rmi [选项] <镜像1> [<镜像2> ...] |
用 ID、镜像名、摘要删除镜像
其中,<镜像> 可以是 镜像短 ID、镜像长 ID、镜像名 或者 镜像摘要。
sudo docker rmi 3745a1731caf
1 | Untagged: centos:latest |
容器
运行容器
有了镜像后,我们就能够以这个镜像为基础启动并运行一个容器。
docker run --name redis_test -p 6379:6379 -d redis
~$ sudo docker run –name redis_test -p 6379:6379 -d redis
5d0fde30bedc6192e77b75bbb8a5a9894b593f7eb58411f0b96a2270872445da
~$ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5d0fde30bedc redis “docker-entrypoint.s…” 45 seconds ago Up 38 seconds 0.0.0.0:6379->6379/tcp redis_test
docker run就是运行容器的命令,运行他的时候可以带一些参数,详细可以通过docke run --help
--rm:这个参数是说容器退出后随之将其删除。默认情况下,为了排障需求,退出的容器并不会立即删除,除非手动docker rm。redis:这是指用redis镜像为基础来启动容器。--name:为容器指定名称。-p:将容器的端口发布到主机.这里就是讲reids容器的6379端口映射到主机上的6379端口(ip:hostPort:containerPort)-d:在后台运行容器并打印容器ID
进入容器内部
进入redis容器内部,运行redis-cli,来操作redis:
docker exec -it containerid /bin/bash
exec:在正在运行的容器中运行命令-it:这是两个参数,一个是-i:交互式操作,保证容器中stdin(一般指键盘输入到缓冲区里的东西)是开放的,一个是-t:告诉docker为要创建的容器分配一个伪tty终端。这样,新创建的容器才能够提供一个交互式shellbash:放在容器id后的是命令,这里我们希望有个交互式 Shell,因此用的是bash。
~$ sudo docker exec -it 5d0fde30bedc /bin/bash
root@5d0fde30bedc:/data# redis-cli
127.0.0.1:6379> set test value
OK
127.0.0.1:6379> get test
“value”
127.0.0.1:6379>
想要退出就按ctrl+d
停止,删除容器
- 停止容器运行:
docker stop containerid - 删除容器:
docker rm containerid删除容器必须要先将容器停止之后. - 删除所有容器: docker rm `sudo docker ps -a -q`
启动,重启容器
启动已经停止运行的容器:
docker start containername或者通过id启动docker start containerid重启容器:
docker restart containername或者docker restart containerid自动重启容器:
如果容器因为某种错误而导致了容器停止运行,还可以通过
--restart标志,让docker自动重新启动该容器。--restart标志会检查容器的退出代码,并根据此来决定是否要重启容器。默认的行为是docker不会容器容器。–restart:参数:
always:无论容器的退出代码是什么,docker 都会自动重启该容器,on-failure:只有当容器退出的代码是非0值的时候,才会自动重启,on-failure可以接受一个可选的重启次数参数,如--restart=on-failure:5.这样,当容器退出代码为非0的时候,docker会尝试自动重启该容器,最多重启5此